Parallelism with Dask#
The dask folks have a very good introduction to dask data structures and parallelism in their dask tutorial. In that tutorial, you’ll get exposure to the general dask architecture, as well as specific hands-on examples with two of the three key dask data structures: dask arrays, and dask dataframes.
The above tutorial does not cover dask bag in any detail – this is a key data structure
that we use to distribute parallel tasks in clustered environments. Here’s a quick demo of
a dask bag and how we use it. A bag is analagous to a standard Python list… let’s start there
with some nomenclature:
Lists and Maps#
A common pattern in Python is a ‘list comprehension’ – a way of transforming a list of values into a new list of values using a transformation pattern.
myList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
newList = [x**2 for x in myList]
newList
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
This feature of python maps an action onto each element in a list. The result is a new list holding the result of each action – one action per element in the list.
The syntax of the above list comprehension is purely for us
humans. The python implementation behind the scenes uses a special built-in python function
called map:
def myFunc(i):
return i**2
list(map(myFunc, myList))
# maps each element of myList to a separate invokation of myFunc.
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
The map() call handles the work of calling myFunc() once each for the elements of myList.
You can see that doing it this way involves a lot of extra hoops and parenthesis to jump through.
Which is why it is almost never written that way.
The list element is given to the function as a positional argument. In essence, the above map is the same as:
result=[]
for x in myList:
result.append(myFunc(x))
result
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Dask Bag#
A dask bag datastructure is much like a list, but it has the map function built into it as
an object method. The invocation is slightly different, but the concept is the same: it
pairs up elements of a list with a function call to execute against those elements. A dask
bag has the ability to spawn the myFunc() calls in parallel, distributing those calls to
workers around the dask cluster.
Let’s look at an example… first, let’s make myFunc() simulate time-consuming work by having
it pause for a while.
from time import sleep
def myFunc(i):
sleep(1) ## Simulates dense computation taking one second
return i**2
This function is one that we want to distribute across a dask compute cluster.
For this small demonstration, we’ll build a cluster on the local host; no need to make a distributed cluster.
import os
import dask.bag as db
from dask.distributed import Client, LocalCluster
cluster = LocalCluster(threads_per_worker=os.cpu_count())
client = Client(cluster)
/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/node.py:187: UserWarning: Port 8787 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 40517 instead
warnings.warn(
# fill the bag with our list of items
myBag = db.from_sequence(myList)
# then 'map' the elements to the worker function we want to execute on each element in the bag
result = myBag.map(myFunc)
Note that this returned immediately (i.e very small execution time). That’s because the computation has not been done yet. Dask is a ‘lazy’ system in which computations are delayed as long as possible.
As with other dask operations, result at this point just contains the ‘task graph’ – what
dask is going to do, and in what order. We can see that task graph with the visualize
method:
result.visualize()
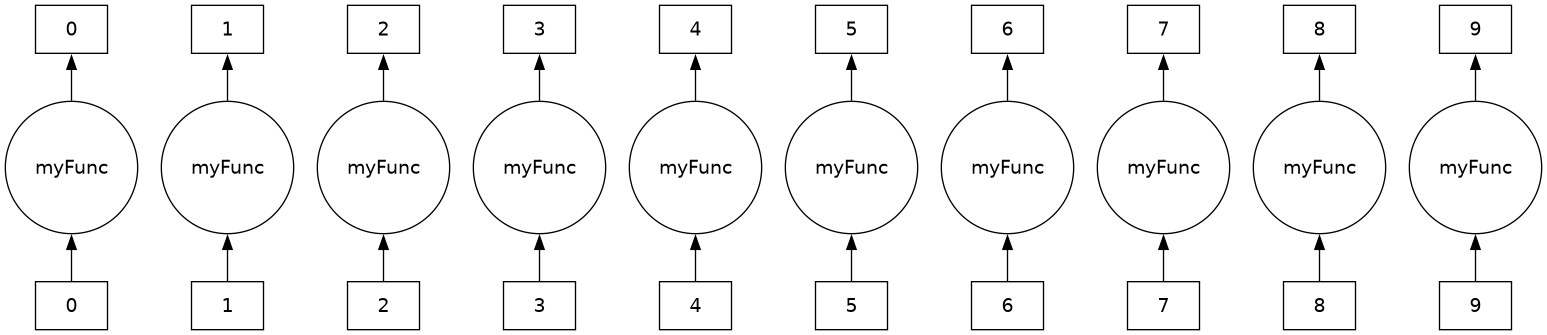
Note that each of those elements is independent from the others, so they can in theory execute in parallel. ‘Thread’ zero will call myFunc with some arguments to produce result zero. Same with threads 1 throuth 9. Because these threads do not depend on one another, they can operate in parallel, on separate workers.
In the original, pure-python operation, these calls to myFunc would be serialized: one at a time.
Let’s compare run times:
%%time
# should take about 10 seconds: one second per call to myFunc
## Pure python mapping:
list( map( myFunc, myList))
CPU times: user 208 ms, sys: 22.9 ms, total: 231 ms
Wall time: 10 s
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
%%time
## using the dask bag task-graph
result.compute()
CPU times: user 79.8 ms, sys: 13.1 ms, total: 92.9 ms
Wall time: 3.1 s
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Note that the pure python execution took right around 10 seconds. Each call to myFunc, remember, is artificially set to take one second each. Calling them serially should take 10 seconds (plus whatever internal overhead python needs).
The dask bag approach took substantially less time. If it were perfectly parallel, the result would have been computed in one second (ten simultaneous executions of myFunc, each taking one second). But that parallelism depends on how many cpus/cores you have. If you only have one core, then parallelism isn’t going to help you – the dispatched workers still need to take turns on the CPU.
If you had 10 cores (the number of elements in the bag), then you might get close to the perfect parallelism. Dask does involve more overhead than pure python in order to achieve its parallelism; the administrative overhead for operating the cluster scheduler will prevent this from being perfectly parallel.
The above example uses a local cluster, meaning that the work is scheduled among the CPUs on the local hardware. Dask can also utilize distributed clusters, meaning that workers can be organized among several computers connected via network. This allows for many more CPUs to attach to a problem, but the overhead of network communication will impact the administrative costs of coordinating the workers.
## shut down cluster scheduler
client.close(); del client
cluster.close(); del cluster
2025-05-27 13:32:36,363 - distributed.worker - ERROR - Failed to communicate with scheduler during heartbeat.
Traceback (most recent call last):
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/comm/tcp.py", line 225, in read
frames_nosplit_nbytes_bin = await stream.read_bytes(fmt_size)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
tornado.iostream.StreamClosedError: Stream is closed
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/worker.py", line 1269, in heartbeat
response = await retry_operation(
^^^^^^^^^^^^^^^^^^^^^^
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/utils_comm.py", line 441, in retry_operation
return await retry(
^^^^^^^^^^^^
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/utils_comm.py", line 420, in retry
return await coro()
^^^^^^^^^^^^
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/core.py", line 1259, in send_recv_from_rpc
return await send_recv(comm=comm, op=key, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/core.py", line 1018, in send_recv
response = await comm.read(deserializers=deserializers)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/comm/tcp.py", line 236, in read
convert_stream_closed_error(self, e)
File "/home/conda/hytest/785d3670-1747942806-104-pangeo/lib/python3.12/site-packages/distributed/comm/tcp.py", line 142, in convert_stream_closed_error
raise CommClosedError(f"in {obj}: {exc}") from exc
distributed.comm.core.CommClosedError: in <TCP (closed) ConnectionPool.heartbeat_worker local=tcp://127.0.0.1:42572 remote=tcp://127.0.0.1:36599>: Stream is closed
Dask Bags in HyTEST Workflows#
This pattern is used extensively in the benchmarking workflows. A series of statistics are calculated for each streamgage in a list of 5000+ gages. With a dask bag (the contents of which is the list of gages), the stats package can be dispatched to workers operating independently and in parallel.